

5+ leading small language models of 2026

With half a decade of experience in creating tech content for education, healthcare, hospitality, and real estate, Nandhini excels at turning complex insights into clear, credible, in-depth, research-backed, and engaging content that helps readers make informed decisions.
Our authors are proven experts in their fields, writing on topics where they have demonstrated expertise. Every piece of content undergoes peer review and validation by industry professionals.
AI Summary
Key Highlights of Leading Small Language Models 2026
This post explores the rise of small language models (LLMs) in 2026 as practical, cost-effective AI solutions for enterprises. The key insight: small models match large ones on many tasks while demanding less compute, memory, and energy. It highlights top models like Llama 2, Falcon Lite, Mistral 7B, Qwen 2, and DistilGPT2, focusing on their task specialization, training data, and efficiency. Designed for on-device, edge, and sustainability use, these models promise scalable AI deployment with lower costs and improved privacy. Readers gain clarity on selecting and optimizing small LLMs for real-world applications.
In 2026, small language models are becoming a central pillar of practical AI deployment as organizations shift from experimental projects to real production use cases. These compact models deliver strong task-level performance while using far less compute, memory, and energy than large general-purpose models, making them more cost-effective and easier to scale. Industry forecasts predict that enterprises will adopt task-specific small models at significantly higher rates than large models, driven by the need for lower inference costs, better contextual accuracy, and enhanced data privacy.
Academic research also confirms that small language models can rival larger counterparts on many real-world tasks through methods such as model compression, pruning, and targeted fine-tuning, enabling high efficiency without sacrificing quality. These models are especially attractive for on-device AI, mobile applications, and edge computing, where real-time responsiveness and reduced infrastructure costs are critical.
As breakthroughs in training techniques and optimization continue to close the performance gap, small language models are positioned to power the next wave of AI adoption in enterprise systems, consumer applications, and sustainability-focused deployments.
Read our blog to see how ColorWhistle envisions AI to help client’s businesses.
5+ leading small language models of 2026
Llama 2 (7B)
Llama 2 is a collection of pre-trained and fine-tuned large language models developed by Meta, ranging from 7 billion to 70 billion parameters. The Llama-2-7B model, specifically, is a 7-billion-parameter model designed to deliver high performance in natural language processing tasks. This model is available for download and use under the Llama 2 Community License Agreement.
Performance and Efficiency
Llama 2 models are trained on 2 trillion tokens and have double the context length of Llama 1. The fine-tuned version, Llama Chat, has been trained on over 1 million human annotations.
Unique Features of Llama-2-7B
- Scalable Architecture: As part of the Llama 2 series, the 7B model benefits from a transformer-based architecture optimized for a range of natural language tasks
- Versatility: The model is suitable for various applications, including text generation, summarization, and comprehension tasks
- Community License: Released under the Llama 2 Community License Agreement, the model is accessible for research and commercial use, subject to the license terms
Limitations and Optimization Needs
- Resource Intensive: Deploying the Llama-2-7B model requires substantial computational resources, including significant GPU memory, which may be a consideration for some users
- Fine-Tuning Requirements: To achieve optimal performance on specific tasks or domains, users may need to fine-tune the model with domain-specific data
- License Compliance: Users must adhere to the Llama 2 Community License Agreement, which includes provisions on usage and distribution
Falcon Lite (7B)
Falcon-7B is a 7-billion-parameter causal decoder-only language model developed by the Technology Innovation Institute (TII). Trained on 1,500 billion tokens from the RefinedWeb dataset, enhanced with curated corpora, it is designed to deliver high performance in natural language processing tasks. The model is available under the Apache 2.0 license, promoting open access and collaboration.
Performance and Efficiency
Falcon-7B outperforms comparable open-source models, such as MPT-7B, StableLM, and RedPajama, due to its extensive training on a diverse dataset. Its architecture is optimized for inference, incorporating FlashAttention and multi-query mechanisms, which enhance computational efficiency and speed.
Unique Features of Falcon-7B
- Extensive Training Data: Utilizes the RefinedWeb dataset, comprising 1,500 billion tokens, to ensure a broad understanding of language
- Optimized Architecture: Features FlashAttention and multi-query mechanisms for efficient inference
- Open-Source Accessibility: Released under the Apache 2.0 license, allowing for commercial use without royalties or restrictions
Limitations and Optimization Needs
- Pretrained Model: As a raw, pre-trained model, Falcon-7B may require further fine-tuning for specific applications to achieve optimal performance
- Language Scope: Primarily trained on English and French data, it may have limited generalization to other languages
- Bias and Fairness: Reflects stereotypes and biases present in web data; users should assess and mitigate potential biases in their applications
Also Read
Mistral 7B
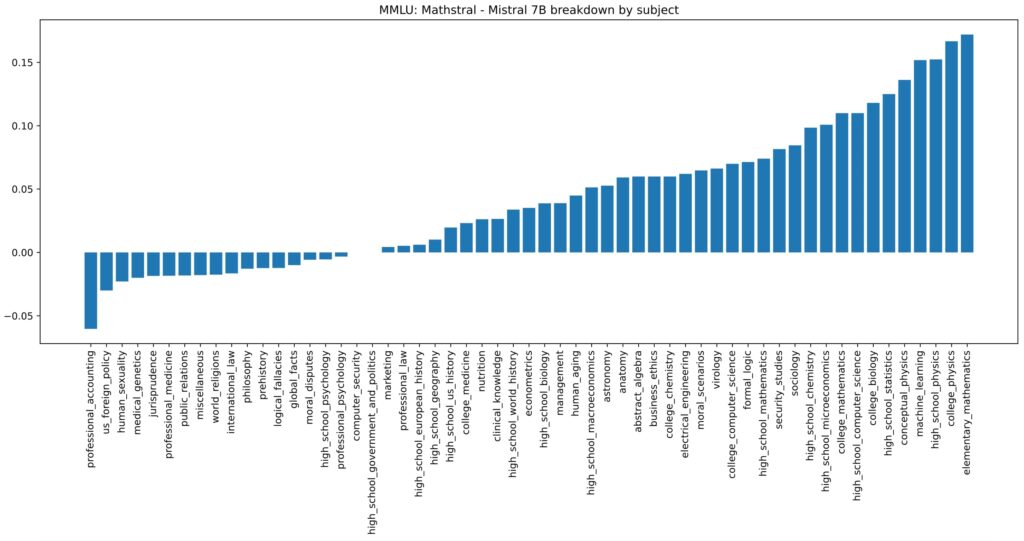
Mistral AI has introduced MathΣtral, a specialized 7-billion-parameter language model designed for mathematical reasoning and scientific discovery. Built upon Mistral 7B, it enhances problem-solving capabilities in STEM disciplines. The model is open-source, allowing researchers and developers to fine-tune and deploy it for academic and scientific applications. Below are the key aspects of MathΣtral
Performance and Efficiency
MathΣtral delivers state-of-the-art performance in mathematical reasoning and problem-solving. It achieves
- 56.6% on the MATH benchmark, which evaluates advanced mathematical problem-solving skills
- 63.47% on the MMLU benchmark, assessing multitask language understanding across various subjects
For improved performance, the model can utilize majority voting and reward model selection, boosting its MATH benchmark score to 68.37% and even 74.59% in optimal conditions. This makes it highly efficient for research-based applications.
Unique Features of Mistral 7B
MathΣtral stands out due to its specialized architecture and enhanced capabilities
- STEM-Specialized Training: Unlike general-purpose models, MathΣtral is fine-tuned for mathematical and scientific tasks, improving its reasoning abilities in these areas
- Extended Context Window: With a 32,000-token capacity, it can handle long mathematical proofs, equations, and problem-solving steps effectively
- Open-Source and Customizable: Released under the Apache 2.0 license, the model’s weights are available on Hugging Face, enabling researchers and developers to fine-tune and integrate it into their projects
Limitations and Optimization Needs
Despite its strengths, MathΣtral has certain limitations and areas for optimization
- Limited General Knowledge: Since it is focused on STEM subjects, it may underperform in broader language-related tasks compared to general-purpose LLMs
- Computation-Intensive for Best Results: The highest accuracy requires additional inference-time techniques like majority voting and ranking methods, which may increase computational costs
- Domain-Specific Optimization Required: While MathΣtral is pre-trained on mathematical tasks, some fine-tuning may be necessary for specialized fields such as physics, engineering, or financial modeling
Qwen 2 (0.5B)
Qwen2-0.5B is a 494-million-parameter language model developed as part of the Qwen2 series. It is designed to offer efficient language processing while maintaining strong performance across various natural language understanding (NLU) and generation (NLG) tasks. The Qwen2 series includes models ranging from 0.5B to 72B parameters, featuring both base and instruction-tuned versions, as well as a Mixture-of-Experts (MoE) model for enhanced scalability.
Performance and Efficiency
Despite its smaller size, Qwen2-0.5B delivers competitive results across multiple benchmarks, demonstrating strong reasoning and comprehension abilities
- MMLU (Massive Multitask Language Understanding): 45.4 scores, showing solid performance across a variety of subjects
- GPT-4-All Benchmark: 37.5 scores, highlighting its effectiveness in open-ended text generation
Its relatively small size allows for fast inference times and lower computational costs, making it a practical choice for deployment in resource-constrained environments.
Unique Features of Qwen2-0.5B
Qwen2-0.5B incorporates several notable features that enhance its usability
- Optimized for Diverse Tasks: Trained on diverse and high-quality datasets, the model is well-suited for tasks like question answering, summarization, and content generation
- Efficient and Lightweight: With under 500M parameters, it balances capability and computational efficiency, making it ideal for on-device applications or cloud-based services with limited resources
- Scalable Model Family: As part of the Qwen2 series, it shares architectural similarities with larger models, allowing users to scale up if more processing power is available
Limitations and Optimization Needs
Although Qwen2-0.5B is efficient and effective, it has certain limitations that should be considered
- Limited Context Window: Compared to larger models, its ability to process long-form text is constrained, which may affect tasks requiring extensive memory
- Performance Trade-offs: While competitive, it does not match larger LLMs in complex reasoning or high-level creative text generation
- Fine-Tuning for Specific Domains: To achieve optimal results in specialized applications, domain-specific fine-tuning may be necessary
DistilGPT 2
Hugging Face has developed DistilGPT2, a distilled version of the Generative Pre-trained Transformer 2 (GPT-2), aiming to provide a lighter and faster model for text generation tasks. By applying knowledge distillation techniques, DistilGPT2 retains much of GPT-2’s language modeling capabilities while being more efficient. Below are the key aspects of DistilGPT2
Performance and Efficiency
DistilGPT2 is designed to offer a balance between performance and computational efficiency
- Model Size and Speed: With 82 million parameters, DistilGPT2 is significantly smaller than the original GPT-2’s 124 million parameters. This reduction results in approximately twice the speed of GPT-2, facilitating faster text generation
- Benchmark Performance: On the WikiText-103 benchmark, DistilGPT2 achieves a perplexity of 21.1 on the test set, compared to GPT-2’s 16.3. While there’s a slight trade-off in perplexity, the efficiency gains make DistilGPT2 suitable for applications where speed and resource utilization are critical
Unique Features of DistilGPT2
DistilGPT2 incorporates several distinctive features
- Knowledge Distillation: The model is trained using knowledge distillation, where DistilGPT2 learns to replicate the behavior of the smallest GPT-2 model. This process enables the retention of essential language understanding while reducing model complexity
- Versatility in Text Generation: Like its predecessor, DistilGPT2 excels in generating coherent and contextually relevant text, making it applicable in various natural language processing tasks such as drafting content, answering questions, and more
- Open-Source Accessibility: Released under the Apache 2.0 license, DistilGPT2 is openly available for integration, fine-tuning, and deployment, encouraging community-driven development and research
Limitations and Optimization Needs
While DistilGPT2 offers notable advantages, certain limitations, and considerations include
- Inherent Biases: As with many language models, DistilGPT2 may reflect biases present in its training data. Users should be cautious of potential biases in generated outputs and consider implementing bias mitigation strategies
- Slight Performance Trade-offs: The reduction in model size leads to a modest increase in perplexity compared to the original GPT-2, which may affect performance in tasks requiring nuanced language understanding
- Domain-Specific Fine-Tuning: For specialized applications, further fine-tuning on relevant datasets may be necessary to enhance performance and ensure the model meets specific domain requirement
DistilGPT2 represents a significant advancement in creating efficient language models and balancing performance with resource utilization. Its open-source nature and versatility make it a valuable tool for developers and researchers in the field of natural language processing.
Also Read
Phi-3 Mini (3.8B)
Phi-3 Mini is a 3.8-billion-parameter small language model developed by Microsoft and optimized for reasoning, instruction following, and code-related tasks. It is designed to deliver strong logical performance while remaining lightweight enough for enterprise and edge deployments.
Performance and Efficiency
Phi-3 Mini demonstrates competitive reasoning and coding performance relative to its size. It supports long-context reasoning and is optimized to run efficiently on limited hardware, including CPUs and smaller GPUs, reducing infrastructure costs.
Unique Features of Phi-3 Mini
- Strong reasoning and mathematical problem-solving capabilities
- Optimized for instruction-following and enterprise workloads
- Designed to run efficiently in constrained environments
Limitations and Optimization Needs
- Not intended for highly creative or open-ended generation
- Performs best when fine-tuned for domain-specific tasks
- Smaller ecosystem compared to long-established open-source models
Gemma 2B
Gemma 2B is a lightweight open language model released by Google, designed for efficiency, multilingual support, and responsible AI deployment. It is part of the Gemma family, which focuses on safe and accessible model design.
Performance and Efficiency
Despite its compact size, Gemma 2B performs well on instruction-following and multilingual benchmarks. Its low memory footprint allows deployment on consumer-grade hardware and mobile devices.
Unique Features of Gemma 2B
- Optimized for multilingual and mobile-first use cases
- Strong alignment with responsible AI and safety practices
- Lightweight architecture suitable for on-device inference
Limitations and Optimization Needs
- Limited capacity for complex reasoning tasks
- Smaller context window compared to mid-size models
- Benefits from task-specific fine-tuning
TinyLlama (1.1B)
TinyLlama is a 1.1-billion-parameter open-source language model designed to replicate the behavior of larger LLaMA-style architectures at a fraction of the size. It is frequently used as a base model for experimentation and domain-specific fine-tuning.
Performance and Efficiency
TinyLlama offers fast inference and low memory usage, making it suitable for lightweight NLP tasks such as classification, summarization, and basic text generation.
Unique Features of TinyLlama
- Extremely lightweight and fast to deploy
- Compatible with LLaMA-style fine-tuning workflows
- Ideal for experimentation and edge environments
Limitations and Optimization Needs
- Limited reasoning and creative generation capabilities
- Smaller context window
- Requires fine-tuning for meaningful task performance
MobileLLaMA (1–3B)
MobileLLaMA is a family of optimized small language models designed specifically for mobile and on-device inference. These models focus on reducing latency, memory usage, and energy consumption.
Performance and Efficiency
MobileLLaMA models are optimized to run efficiently on smartphones and embedded systems, delivering acceptable performance for conversational and utility-focused tasks.
Unique Features of MobileLLaMA
- Optimized for mobile CPUs and NPUs
- Low latency and reduced power consumption
- Designed for offline and privacy-preserving AI use cases
Limitations and Optimization Needs
- Not suitable for large-scale reasoning or long-context tasks
- Performance varies depending on hardware
- Requires careful quantization and optimization
OpenELM (270M–3B)
OpenELM is a family of small language models introduced by Apple, focusing on transparency, efficiency, and on-device AI. It uses layer-wise parameter allocation to improve performance without increasing model size.
Performance and Efficiency
OpenELM models deliver strong performance relative to their size and are optimized for low-latency inference on consumer devices, especially Apple hardware.
Unique Features of OpenELM
- Layer-wise parameter allocation for efficiency
- Designed for on-device and privacy-first AI
- Open research focus with transparent training methodology
Limitations and Optimization Needs
- Limited ecosystem outside Apple-centric environments
- Smaller community compared to mainstream open-source models
- Best suited for controlled, on-device use cases
Wrap-Up
Small language models in 2026 reflect a clear shift from scale-driven AI to efficiency-driven deployment. Models such as Llama 2, Mistral 7B, Qwen 2, Phi-3 Mini, Gemma, and OpenELM prove that strong language understanding, reasoning, and instruction following can be achieved with far lower compute and operational cost.
As enterprises move from pilots to production, compact and task-specific models are becoming the default choice for on-device AI, edge computing, and privacy-sensitive applications. Continued progress in fine-tuning, quantization, and optimization is steadily closing the performance gap with larger models.
Looking ahead, successful AI systems will be defined by how well models fit real-world constraints rather than by parameter count. Small language models are no longer an alternative. They are the foundation of scalable, practical AI for the years ahead.
Browse our ColorWhistle page for more related content and learn about our services. To contact us and learn more about our services, please visit our Contact Us page.
What’s Next?
Now that you’ve had the chance to explore our blog, it’s time to take the next step and see what opportunities await





